AIStore: Data Analysis w/ DataFrames
AIStore: Data Analysis w/ DataFrames
Dask is a new and flexible open-source Python library for parallel/distributed computing and optimized memory usage. Dask extends many of today’s popular Python libraries providing scalability with ease of usability.
This technical blog will dive into Dask DataFrames, a data structure built on and in parallel with Pandas DataFrames, and how it can be used in nearly identical ways as Pandas DataFrames to analyze and mutate tabular data while offering better performance.
Why Dask?
-
Python Popularity
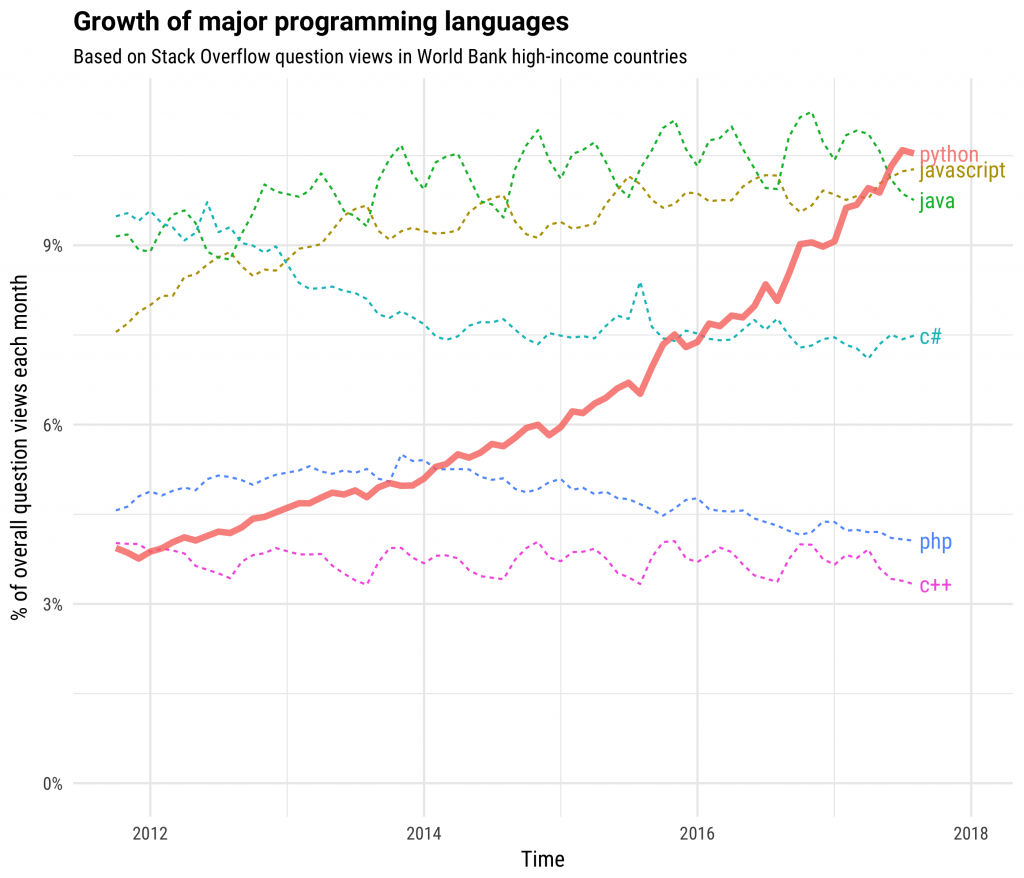
Python’s popularity has skyrocketed over the past few years, especially with data scientists and machine learning developers. This is largely due to Python’s extensive and mature collection of libraries for data science and machine learning, such as
Pandas,NumPy,Scikit-Learn,MatPlotLib,PyTorch, and more.Dask integrates these Python-based libraries, providing scalability with little to no changes in usage.
-
Scalability
Dask effectively scales Python code from a single machine up to a distributed cluster.
Dask leaves behind a low-memory footprint, loading data by chunks as required and throwing away any chunks that are not immediately needed. This means that relatively low-power laptops and desktops can load and handle datasets that would normally be considered too large. Additionally, Dask can leverage the multiple CPU cores found in most modern day laptops and desktops, providing an added performance boost.
For large distributed clusters consisting of many machines, Dask is able to efficiently scale large, complex computations across those many machines. Dask breaks up these large computations and efficiently allocates them across distributed hardware.
-
Familiar API
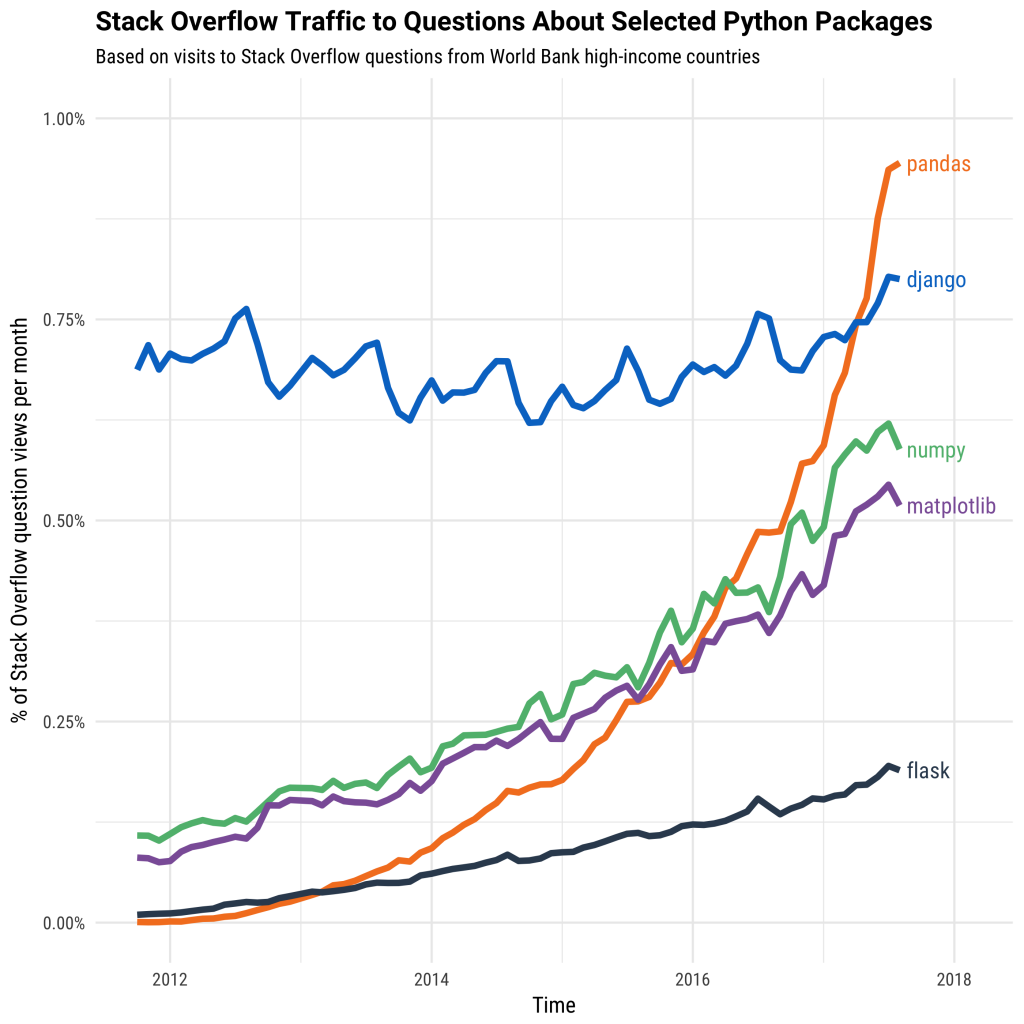
The above mentioned Python libraries have grown immensely in popularity as of recent. However, most of them were not designed to scale beyond a single machine nor with the exponentional growth of dataset sizes. Many of them were developed before big data use-cases became prevalent and can’t process today’s larger datasets as a result. Even Pandas, one of the most popular Python libraries available today, struggles to perform with larger datasets.
Dask allows you to natively scale these familiar libraries and tools for larger datasets while limiting change in usage.
Data Analysis w/ Dask DataFrames
The Dask DataFrame is a data structure based on the pandas.dataframe (data structure) representing two-dimensional, size-mutable tabular data. Dask DataFrames consist of many Pandas DataFrames arranged along the index. In fact, the Dask DataFrame API copies the Pandas DataFrame API, and should be very familiar to previous Pandas users.
The dask.dataframe library, and most other Dask libraries, supports data access via HTTP(s). AIStore, on the other hand, provides both native and Amazon S3 compatible REST API, which means that data stored on AIStore can be accessed and used directly from/by Dask clients.
We can instantiate a Dask DataFrame, loading a sample CSV residing in an AIStore bucket as follows:
import dask.dataframe as dd
import os
AIS_ENDPOINT = os.environ["AIS_ENDPOINT"]
def read_csv_ais(bck_name: str, obj_name: str):
return dd.read_csv(f"{AIS_ENDPOINT}/v1/objects/{bck_name}/{obj_name}")
# Load CSV from AIStore bucket
df = read_csv_ais(bck_name="dask-demo-bucket", obj_name="zillow.csv")
Dask DataFrames are lazy, meaning that the data is only loaded when needed. Dask DataFrames can automatically use data partitioned between RAM and disk, as well data distributed across multiple nodes in a cluster. Dask decides how to compute the results and decides where the best place is to run the actual computation based on resource availability.
When a Dask DataFrame is instantiated, only the first partition of data is loaded into memory (for preview):
# Preview data (first few rows) in memory
df.head()
The rest of the data is only loaded into memory when a computation is made. The following computations do not execute until the compute() method is called, at which point only the necessary parts of the data are pulled and loaded into memory:
# Simple statistics
mean_price = df[' "List Price ($)"'].mean()
mean_size = df[' "Living Space (sq ft)"'].mean()
mean_bed_count = df[' "Beds"'].mean()
std_price = df[' "List Price ($)"'].std()
std_size = df[' "Living Space (sq ft)"'].std()
std_bed_count = df[' "Beds"'].std()
# Computations are executed
dd.compute({"mean_price": mean_price, "mean_bed_count": bed_sum, "mean_size": mean_size, "std_price": std_price, "std_size", "std_bed_count": std_bed_count})
Dask DataFrames also support more complex computations familiar to previous Pandas users such as calculating statistics by group and filtering rows:
# Mean list price of homes grouped by bed count
df.groupby(' "Baths"')[' "List Price ($)"'].mean().compute()
# Filtering data to a subset of only homes built after 2000
filtered_df = df[df[' "Year"'] > 2000]
For an interactive demonstration of the Dask
DataFramefeatures shown in this article (and more), please refer to the Dask AIStore Demo (Jupyter Notebook).