The Many Lives of a Dataset Called 'data'
For whatever reason, a bucket called s3://data shows up with remarkable frequency as we deploy AIStore (AIS) clusters and populate them with user datasets. Likely for the same reason that password = password remains a popular choice.
At NVIDIA, for example, SwiftStack (an S3-compatible object store) is widely used internally. But it is rarely present alone. Other S3-compatible systems appear more often than not: cloud accounts, regional replicas, compliance copies. It is a rule rather than the exception for several storage backends to quietly coexist in workloads run by any given team.
Hence, same-name datasets get copied, mutated, and passed across accounts, eventually finding their way back to us for concurrent use - e.g., s3://data in its many incarnations.
Same bucket name.
Different endpoints.
Different credentials.
Different contents.
Same Name, Many Buckets
In real deployments, what s3://data actually refers to often looks like this:
s3://data exists in:
├── SwiftStack (on-prem)
├── OCI (region ABC)
├── AWS S3 (us-east-1)
├── (and more)
From a human perspective, these buckets feel interchangeable. From a system’s perspective, they absolutely are not.
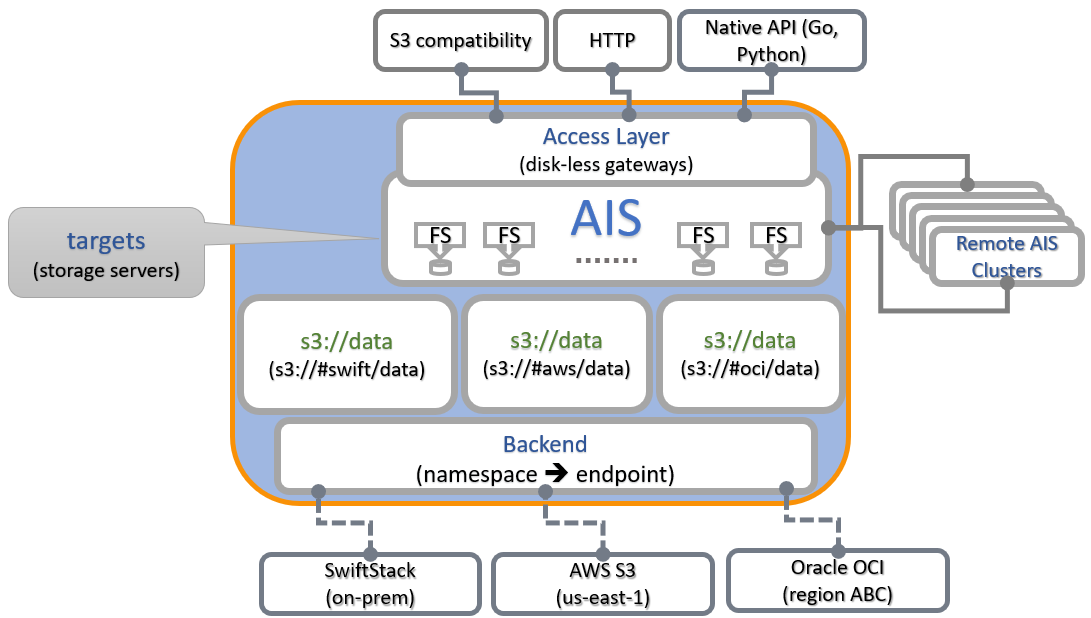
What’s in the Name
Traditional object storage APIs quietly assume that a bucket name uniquely identifies a dataset. That assumption breaks down the moment environments span multiple providers.
In AIS, a bucket is a triplet (see below) with properties:
┌────────── Bucket Identity ───────────┐
│ ( provider, namespace, bucket name ) │
└────────────────┬─────────────────────┘
┌─────────┴─────────┐
│ bucket properties │
└───────────────────┘
Two buckets may share the same name and the same provider, yet belong to different namespaces - and therefore represent entirely different datasets. Credentials, policies, lifecycle rules, and contents remain isolated.
Bucket namespaces are not necessarily static (although they usually are). In AIS, namespace resolution itself can be a runtime decision that’d entail distributing updated bucket metadata - typically a split-second operation.
Dynamic Binding
Separately from namespace, AIS allows a logical bucket to be bound to another bucket as its backing data source.
Note: dynamic binding is not request forwarding or caching. It specifies where a dataset physically resides and how it is accessed remotely.
A logical bucket (e.g., ais://my-training-data) may source its contents from:
- an on-prem S3-compatible system,
- a public cloud bucket,
- a regional replica,
- or a derived dataset produced by a processing pipeline.
Consider two related datasets:
- Original: raw images, audio, or video with minimal labeling
- Processed: augmented, re-labeled, and reordered for efficient training
Both represent the same logical corpus. Training code references a single name: ais://my-training-data.
At runtime, the platform decides which backing data to bind:
- training --> processed dataset
- validation --> raw dataset
- debugging --> local copy (or a subset thereof)
- compliance --> immutable regional mirror
┌─────────────────────────────────────────────┐
│ Application │
│ ais://my-training-data │
└───────────────────────┬─────────────────────┘
│
┌───────────────────────┴─────────────────────┐
│ Bucket Identity │
│ (provider + namespace + bucket name) │
└───────────────────────┬─────────────────────┘
│
┌───────────────────────┴─────────────────────┐
│ Backend Binding │
│ (at runtime) │
└───────────────────────┬─────────────────────┘
- (current binding)
┌──────────────┬────────┴─────┬───────────────┐
│ SwiftStack │ AWS S3 │ OCI │
│ s3://data │ s3://data │ s3://data │
└──────────────┴──────────────┴───────────────┘
Recap
Bucket names are not identities.
Dataset selection is a configuration and/or runtime decision, not an application concern.
Infrastructure must absorb the complexity.
References
PS. I’ve changed SwiftStack, OCI and AWS specifics in this post; the underlying problem and the solution - are real.