Distributed Sort (dSort)
Dsort is extension for AIStore. It was designed to perform map-reduce like operations on terabytes and petabytes of AI datasets. As a part of the whole system, Dsort is capable of taking advantage of objects stored on AIStore without much overhead.
AI datasets are usually stored in tarballs, zip objects, msgpacks or tf-records. Focusing only on these types of files and specific workload allows us to tweak performance without too much tradeoffs.
Capabilities
Example of map-reduce like operation which can be performed on dSort is shuffling (in particular sorting) all objects across all shards by a given algorithm.
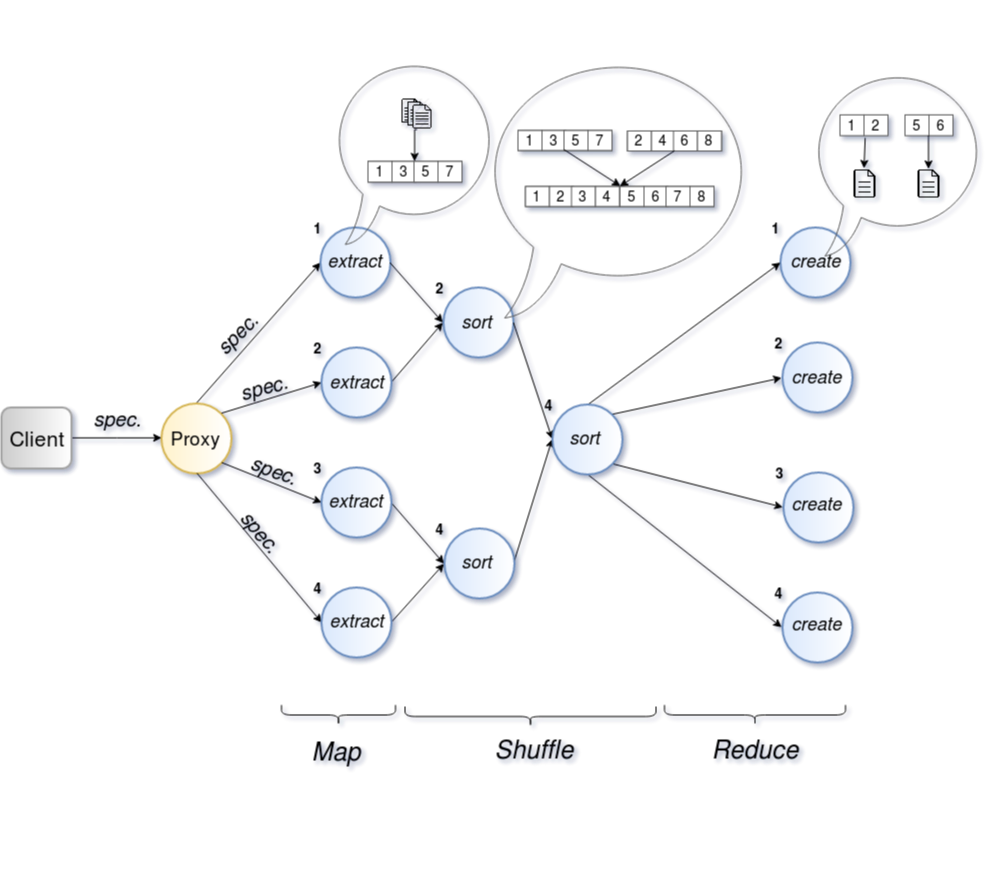
We allow for output shards to be different size than input shards, thus a user is also able to reshard the objects. This means that output shards can contain more or less objects inside the shard than in the input shard, depending on requested sizes of the shards.
The result of such an operation would mean that we could get output shards with different sizes with objects that are shuffled across all the shards, which would then be ready to be processed by a machine learning script/model.
Terms
Object - single piece of data. In tarballs and zip files, an object is single file contained in this type of archives. In msgpack (assuming that msgpack file is stream of dictionaries) object is single dictionary.
Shard - collection of objects. In tarballs and zip files, a shard is whole archive. In msgpack is the whole msgpack file.
We distinguish two kinds of shards: input and output. Input shards, as the name says, it is given as an input for the dSort operation. Output on the other hand is something that is the result of the operation. Output shards can differ from input shards in many ways: size, number of objects, names etc.
Shards are assumed to be already on AIStore cluster or somewhere in a remote bucket so that AIStore can access them. Output shards will always be placed in the same bucket and directory as the input shards - accessing them after completed dSort, is the same as input shards but of course with different names.
Record - abstracts multiple objects with same key name into single structure. Records are inseparable which means if they come from single shard they will also be in output shard together.
Eg. if we have a tarball which contains files named: file1.txt, file1.png,
file2.png, then we would have 2 records: one for file1 and one for
file2.
Algorithm - the sorting algorithm applied during the sorting phase of dSort. After dSort execution, all records within a shard, or across shards with adjacent indices, are guaranteed to be sorted according to the specified algorithm’s order.
External Key Map (EKM) - a dSort feature that allows users to precisely control how records are packed into output shards. EKM provides a flexible mechanism to map each individual record to a specific shard based on rules defined in an external file.
Extraction phase - dSort has multiple phases in which it does the whole
operation. The first of them is extraction. In this phase, dSort is reading
input shards and looks inside them to get to the objects and metadata. Objects
and their metadata are then extracted to either disk or memory so that dSort
won’t need another pass of the whole data set again. This way Dsort can create
Records which are then used for the whole operation as the main source of
information (like location of the objects, sizes, names etc.). Extraction phase
is very critical because it does I/O operations. To make the following phases
faster, we added support for extraction to memory so that requests for the given
objects will be served from RAM instead of disk. The user can specify how much
memory can be used for the extraction phase, either in raw numbers like 1GB or
percentages 60%.
As mentioned this operation does a lot of I/O operations. To allow the user to have better control over the disk usage, we have provided a concurrency parameter which limits the number of shards that can be read at the same time.
Sorting phase - in this phase, the metadata is processed and aggregated on a single machine. It can be processed in various ways: sorting, shuffling, resizing etc. This is usually the fastest phase but still uses a lot of CPU processing power, to process the metadata.
The merging of metadata is performed in multiple steps to distribute the load across machines.
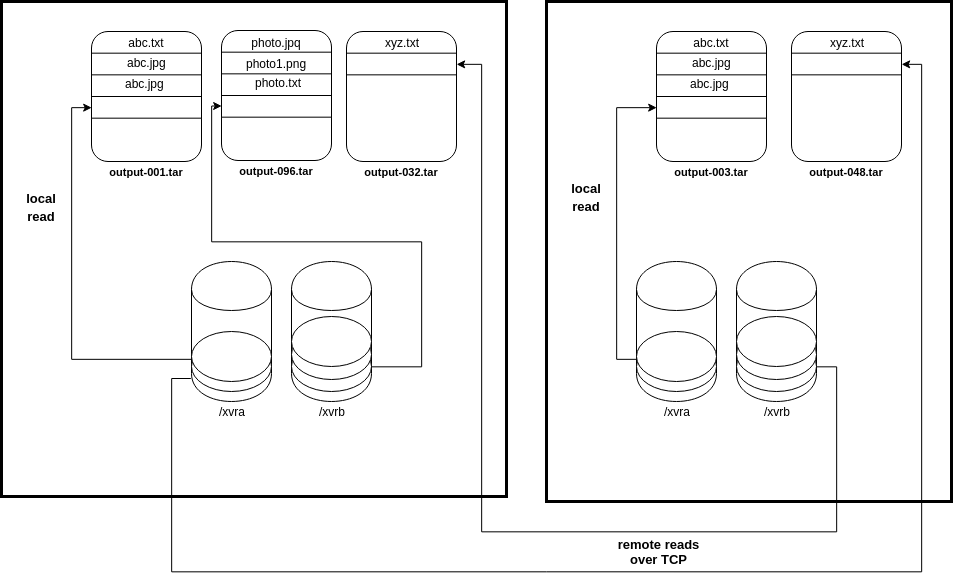
Creation phase - it is last phase of dSort where output shards are created. Like the extraction phase, the creation phase is bottlenecked by disk and I/O. Additionally, this phase may use a lot of bandwidth because objects may have been extracted on different machine.
Similarly to the extraction phase we expose a concurrency parameter for the user, to limit number of shards created simultaneously.
Shards are created from local records or remote records. Local records are records which were extracted on the machine where the shard is being created, and similarly, remote records are records which were extracted on different machines. This means that a single machine will typically have a lot of read/write operations on the disk coming from either local or remote requests. This is why tweaking the concurrency parameter is really important and can have great impact on performance. We strongly advise to make couple of tests on small load to see what value of this parameter will result in the best performance. Eg. tests shown that on setup: 10x targets, 10x disks on each target, the best concurrency value is 60.
The other thing that user needs to remember is that when running multiple dSort operations at once, it might be better to set the concurrency parameter to something lower since both of the operation may use disk at the same time. A higher concurrency parameter can result in performance degradation.
Metrics - user can monitor whole operation thanks to metrics. Metrics provide an overview of what is happening in the cluster, for example: which phase is currently running, how much time has been spent on each phase, etc. There are many metrics (numbers and stats) recorded for each of the phases.
Metrics
Dsort allows users to fetch the statistics of a given job (either started/running or already finished). Each phase has different, specific metrics which can be monitored. Description of metrics returned for single node:
local_extractionstarted_time- timestamp when the local extraction has started.end_time- timestamp when the local extraction has finished.elapsed- duration (in seconds) of the local extraction phase.running- informs if the phase is currently running.finished- informs if the phase has finished.total_count- static number of shards which needs to be scanned - informs what is the expected number of input shards.extracted_count- number of shards extracted/processed by given node. This number can differ from node to node since shards may not be equally distributed.extracted_size- size of extracted/processed shards by given node.extracted_record_count- number of records extracted (in total) from all processed shards.extracted_to_disk_count- number of records extracted (in total) and saved to the disk (there was not enough space to save them in memory).extracted_to_disk_size- size of extracted records which were saved to the disk.single_shard_stats- statistics about single shard processing.total_ms- total number of milliseconds spent extracting all shards.count- number of extracted shards.min_ms- shortest duration of extracting a shard (in milliseconds).max_ms- longest duration of extracting a shard (in milliseconds).avg_ms- average duration of extracting a shard (in milliseconds).min_throughput- minimum throughput of extracting a shard (in bytes per second).max_throughput- maximum throughput of extracting a shard (in bytes per second).avg_throughput- average throughput of extracting a shard (in bytes per second).
meta_sortingstarted_time- timestamp when the meta sorting has started.end_time- timestamp when the meta sorting has finished.elapsed- duration (in seconds) of the meta sorting phase.running- informs if the phase is currently running.finished- informs if the phase has finished.sent_stats- statistics about sending records to other nodes.total_ms- total number of milliseconds spent on sending the records.count- number of records sent to other targets.min_ms- shortest duration of sending the records (in milliseconds).max_ms- longest duration of sending the records (in milliseconds).avg_ms- average duration of sending the records (in milliseconds).
recv_stats- statistics about receiving records from other nodes.total_ms- total number of milliseconds spent on receiving the records from nodes.count- number of records received from other targets.min_ms- shortest duration of receiving the records (in milliseconds).max_ms- longest duration of receiving the records (in milliseconds).avg_ms- average duration of receiving the records (in milliseconds).
shard_creationstarted_time- timestamp when the shard creation has started.end_time- timestamp when the shard creation has finished.elapsed- duration (in seconds) of the shard creation phase.running- informs if the phase is currently running.finished- informs if the phase has finished.to_create- number of shards which needs to be created on given node.created_count- number of shards already created.moved_shard_count- number of shards moved from the node to another one (it sometimes makes sense to create shards locally and send it via network).req_stats- statistics about sending requests for records.total_ms- total number of milliseconds spent on sending requests for records from other nodes.count- number of requested records.min_ms- shortest duration of sending a request (in milliseconds).max_ms- longest duration of sending a request (in milliseconds).avg_ms- average duration of sending a request (in milliseconds).
resp_stats- statistics about waiting for the records.total_ms- total number of milliseconds spent on waiting for the records from other nodes.count- number of records received from other nodes.min_ms- shortest duration of waiting for a record (in milliseconds).max_ms- longest duration of waiting for a record (in milliseconds).avg_ms- average duration of waiting for a record (in milliseconds).
local_send_stats- statistics about sending record content to other target.total_ms- total number of milliseconds spent on writing the record content to the wire.count- number of records received from other nodes.min_ms- shortest duration of waiting for a record content to written into the wire (in milliseconds).max_ms- longest duration of waiting for a record content to written into the wire (in milliseconds).avg_ms- average duration of waiting for a record content to written into the wire (in milliseconds).min_throughput- minimum throughput of writing record content into the wire (in bytes per second).max_throughput- maximum throughput of writing record content into the wire (in bytes per second).avg_throughput- average throughput of writing record content into the wire (in bytes per second).
local_recv_stats- statistics receiving record content from other target.total_ms- total number of milliseconds spent on receiving the record content from the wire.count- number of records received from other nodes.min_ms- shortest duration of waiting for a record content to be read from the wire (in milliseconds).max_ms- longest duration of waiting for a record content to be read from the wire (in milliseconds).avg_ms- average duration of waiting for a record content to be read from the wire (in milliseconds).min_throughput- minimum throughput of reading record content from the wire (in bytes per second).max_throughput- maximum throughput of reading record content from the wire (in bytes per second).avg_throughput- average throughput of reading record content from the wire (in bytes per second).
single_shard_stats- statistics about single shard creation.total_ms- total number of milliseconds spent creating all shards.count- number of created shards.min_ms- shortest duration of creating a shard (in milliseconds).max_ms- longest duration of creating a shard (in milliseconds).avg_ms- average duration of creating a shard (in milliseconds).min_throughput- minimum throughput of creating a shard (in bytes per second).max_throughput- maximum throughput of creating a shard (in bytes per second).avg_throughput- average throughput of creating a shard (in bytes per second).
aborted- informs if the job has been aborted.archived- informs if the job has finished and was archived to journal.description- description of the job.
Example output for single node:
{
"local_extraction": {
"started_time": "2019-06-17T12:27:25.102691781+02:00",
"end_time": "2019-06-17T12:28:04.982017787+02:00",
"elapsed": 39,
"running": false,
"finished": true,
"total_count": 1000,
"extracted_count": 182,
"extracted_size": 4771020800,
"extracted_record_count": 9100,
"extracted_to_disk_count": 4,
"extracted_to_disk_size": 104857600,
"single_shard_stats": {
"total_ms": 251417,
"count": 182,
"min_ms": 30,
"max_ms": 2696,
"avg_ms": 1381,
"min_throughput": 9721724,
"max_throughput": 847903603,
"avg_throughput": 50169799
}
},
"meta_sorting": {
"started_time": "2019-06-17T12:28:04.982041542+02:00",
"end_time": "2019-06-17T12:28:05.336979995+02:00",
"elapsed": 0,
"running": false,
"finished": true,
"sent_stats": {
"total_ms": 99,
"count": 1,
"min_ms": 99,
"max_ms": 99,
"avg_ms": 99
},
"recv_stats": {
"total_ms": 246,
"count": 1,
"min_ms": 246,
"max_ms": 246,
"avg_ms": 246
}
},
"shard_creation": {
"started_time": "2019-06-17T12:28:05.725630555+02:00",
"end_time": "2019-06-17T12:29:19.108651924+02:00",
"elapsed": 73,
"running": false,
"finished": true,
"to_create": 9988,
"created_count": 9988,
"moved_shard_count": 0,
"req_stats": {
"total_ms": 160,
"count": 8190,
"min_ms": 0,
"max_ms": 20,
"avg_ms": 0
},
"resp_stats": {
"total_ms": 4323665,
"count": 8190,
"min_ms": 0,
"max_ms": 6829,
"avg_ms": 527
},
"single_shard_stats": {
"total_ms": 4487385,
"count": 9988,
"min_ms": 0,
"max_ms": 6829,
"avg_ms": 449,
"min_throughput": 76989,
"max_throughput": 709852568,
"avg_throughput": 98584381
}
},
"aborted": false,
"archived": true
}
API
You can use the AIS’s CLI to start, abort, retrieve metrics or list dSort jobs. It is also possible generate random dataset to test dSort’s capabilities.
Config
| Config value | Default value | Description |
|---|---|---|
duplicated_records |
“ignore” | what to do when duplicated records are found: “ignore” - ignore and continue, “warn” - notify a user and continue, “abort” - abort dSort operation |
missing_shards |
“ignore” | what to do when missing shards are detected: “ignore” - ignore and continue, “warn” - notify a user and continue, “abort” - abort dSort operation |
ekm_malformed_line |
“abort” | what to do when extraction key map notices a malformed line: “ignore” - ignore and continue, “warn” - notify a user and continue, “abort” - abort dSort operation |
ekm_missing_key |
“abort” | what to do when extraction key map have a missing key: “ignore” - ignore and continue, “warn” - notify a user and continue, “abort” - abort dSort operation |
call_timeout |
“10m” | a maximum time a target waits for another target to respond |
default_max_mem_usage |
“80%” | a maximum amount of memory used by running dSort. Can be set as a percent of total memory(e.g 80%) or as the number of bytes(e.g, 12G) |
dsorter_mem_threshold |
“100GB” | minimum free memory threshold which will activate specialized dsorter type which uses memory in creation phase - benchmarks shows that this type of dsorter behaves better than general type |
compression |
“never” | LZ4 compression parameters used when dSort sends its shards over network. Values: “never” - disables, “always” - compress all data, or a set of rules for LZ4, e.g “ratio=1.2” means enable compression from the start but disable when average compression ratio drops below 1.2 to save CPU resources |
To clear what these values means we have couple examples to showcase certain scenarios.
Examples
default_max_mem_usage
Lets assume that we have N targets, where each target has YGB of RAM and default_max_mem_usage is set to 80%.
So dSort can allocate memory until the number of memory used (total in the system) is below 80% * YGB.
What this means is that regardless of how much other subsystems or programs working at the same instance use memory, the dSort will never allocate memory if the watermark is reached.
For example if some other program already allocated 90% * YGB memory (only 10% is left), then dSort will not allocate any memory since it will notice that the watermark is already exceeded.
dsorter_mem_threshold
Dsort has implemented for now 2 different types of so called “dsorter”: dsorter_mem and dsorter_general.
These two implementations use memory, disks and network a little bit differently and are designated to different use cases.
By default dsorter_general is used as it was implemented for all types of workloads.
It is allocates memory during the first phase of dSort and uses it in the last phase.
dsorter_mem was implemented in mind to speed up the creation phase which is usually a biggest bottleneck.
It has specific way of building shards in memory and then persisting them do the disk.
This makes this dsorter memory oriented and it is required for it to have enough memory to build the shards.
To determine which dsorter to use we have introduced a heuristic which tries to determine when it is best to use dsorter_mem instead of dsorter_general.
Config value dsorter_mem_threshold sets the threshold above which the dsorter_mem will be used.
If all targets have max memory usage (see default_max_mem_usage) above the dsorter_mem_threshold then dsorter_mem is chosen for the dSort job.
For example if each target has YGB of RAM, default_max_mem_usage is set to 80% and dsorter_mem_threshold is set to 100GB then as long as on all targets 80% * Y > 100GB then dsorter_mem will be used.