Backend Providers
Introduction
Terminology first:
Backend Provider is a designed-in backend interface abstraction and, simultaneously, an API-supported option that allows to delineate between “remote” and “local” buckets with respect to a given AIS cluster.
AIStore natively integrates with multiple backend providers:
| Backend | Schema(s) | Description |
|---|---|---|
ais |
ais://, ais://@remote_uuid |
AIStore bucket provider, can also refer to remote AIS cluster |
aws |
aws://, s3:// |
Amazon Cloud Storage |
azure |
azure://, az:// |
Azure Cloud Storage |
gcp |
gcp://, gs:// |
Google Cloud Storage |
oci |
oc://, oci:// |
Oracle Cloud Storage1 |
ht |
ht:// |
HTTP(S) based dataset |
Native integration, in turn, implies:
- utilizing vendor’s SDK libraries to operate on the respective remote backends;
- providing unified namespace (where, e.g., two same-name buckets from different backends can co-exist with no conflicts);
- on-the-fly populating AIS own bucket metadata with the properties of remote buckets.
The last bullet deserves a little more explanation. First, there’s a piece of cluster-wide metadata that we call BMD. Like every other type of metadata, BMD is versioned, checksummed, and replicated - the process that is carried out by the currently elected primary.
BMD contains all bucket definitions and per-bucket configurable management policies - local and remote.
Here’s what happens upon the very first (read or write or list, etc.) access to a remote bucket that is not yet in the BMD:
- Behind the scenes, AIS will try to confirm the bucket’s existence and accessibility.
- If confirmed, AIS will atomically add the bucket to the BMD (along with its remote properties).
- Once all of the above is set and done, AIS will go ahead to perform that original (read or write or list, etc.) operation
There are advanced-usage type options to skip Steps 1. and 2. above - see e.g.
LisObjsMsg flags
The full taxonomy of the supported backends is shown below (and note that AIS supports itself on the back as well):
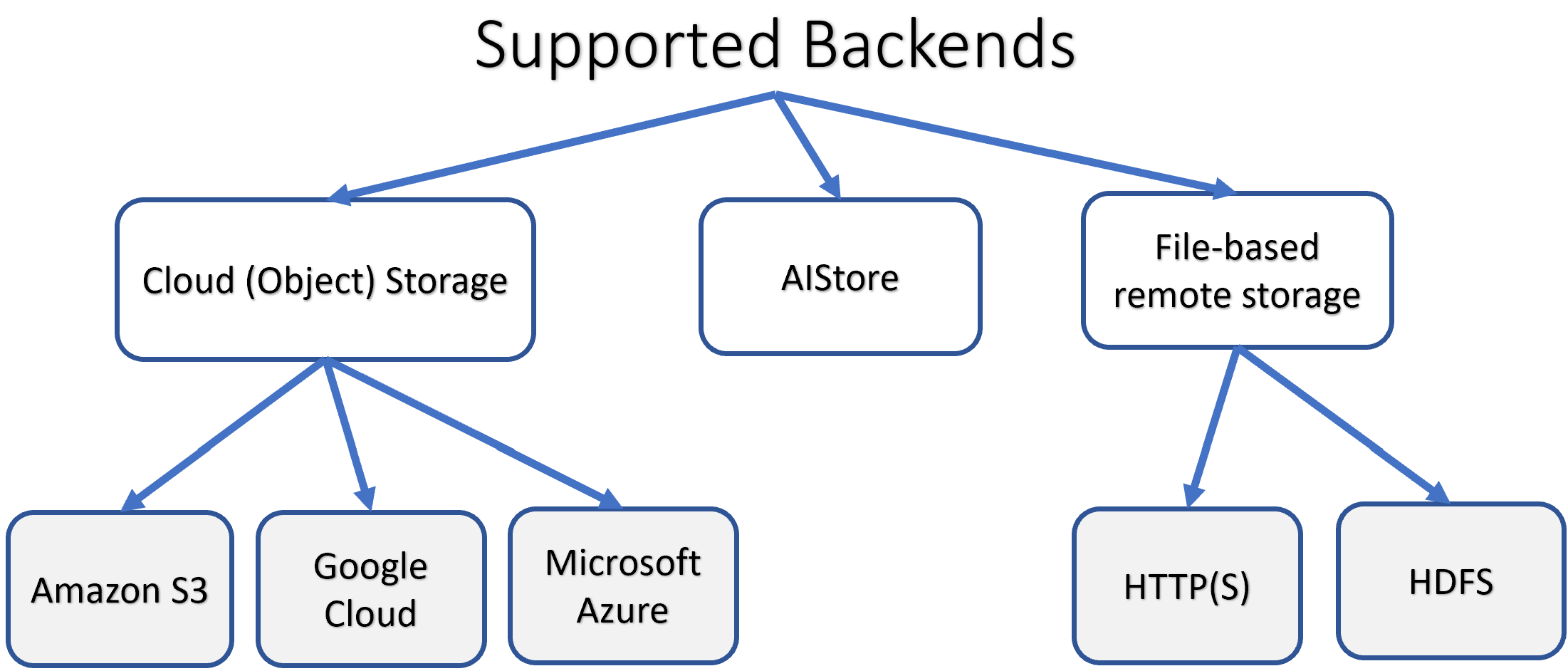
For types of supported buckets (AIS, Cloud, remote AIS, etc.), bucket identity, properties, lifecycle, and associated policies, storage services and usage examples, see the comprehensive:
And further:
Remote AIS cluster
In addition to the listed above 3rd party Cloud storages and non-Cloud HTTP(S) backend, any given pair of AIS clusters can be organized in a way where one cluster would be providing fully-accessible backend to another.
Terminology:
| Term | Comment |
|---|---|
attach remote cluster |
Allow one cluster to see remote datasets, cache those datasets on demand, copy remote buckets, list, create, and destroy remote buckets, read and write remote buckets, etc. |
detach remote cluster |
Operation that (as the name implies) removes the corresponding attachment |
alias |
An optional user-friendly alias that can be assigned at attachment time and be further used in all subsequent operations instead of the remote cluster’s UUID |
global namespace |
Refers to the capability to unambiguously indicate and access any dataset in an arbitrary network (or DAG, to be precise) of AIS clusters whereby some clusters are attached to another ones. By attaching AIS clusters we are, effectively and ad-hoc, forming a unified global namespace of all individually hosted datasets. |
Example working with remote AIS cluster (as well as easy-to-use scripts) can be found in the README for developers.
Unified Global Namespace
Examples first. The following two commands attach and then show remote cluster at the addressmy.remote.ais:51080:
$ ais cluster remote-attach alias111=http://my.remote.ais:51080
Remote cluster (alias111=http://my.remote.ais:51080) successfully attached
$ ais show remote-cluster
UUID URL Alias Primary Smap Targets Online
eKyvPyHr my.remote.ais:51080 alias111 p[80381p11080] v27 10 yes
Notice two aspects of this:
- user-defined aliasing whereby a user can assign an arbitrary name (aka alias) to a given remote cluster
- the remote cluster does not have to be online at attachment time; offline or currently not reachable clusters are shown as follows:
$ ais show remote-cluster
UUID URL Alias Primary Smap Targets Online
eKyvPyHr my.remote.ais:51080 alias111 p[primary1] v27 10 no
<alias222> <other.remote.ais:51080> n/a n/a n/a no
Notice the difference between the first and the second lines in the printout above: while both clusters appear to be currently offline (see the rightmost column), the first one was accessible at some earlier time and therefore we do show that it has (in this example) 10 storage nodes and other details.
To detach any of the previously configured association, simply run:
$ ais cluster remote-detach alias111
$ ais show remote-cluster
UUID URL Alias Primary Smap Targets Online
<alias222> <other.remote.ais:51080> n/a n/a n/a no
Configuration-wise, the following two examples specify a single-URL and multi-URL attachments that can be also be configured prior to runtime (or can be added at runtime via the ais remote attach CLI as shown above):
-
Example: single URL
"backend": { "ais": { "remote-cluster-alias": ["http://10.233.84.233:51080"] } } -
Example: multiple URL
"backend": { "ais": { "remote-cluster-alias": [ "http://10.233.84.217", "https://cluster.aistore.org" ] } }
Multiple remote URLs can be provided for the same typical reasons that include fault tolerance. However, once connected we will rely on the remote cluster map to retry upon connection errors and load balance.
For more usage examples, please see:
And one more comment:
You can run ais cluster remote-attach and/or ais show remote-cluster CLI to refresh remote configuration: check availability and reload remote cluster maps.
In other words, repeating the same ais cluster remote-attach command will have the side effect of refreshing all the currently configured attachments.
Or, use ais show remote-cluster CLI for the same exact purpose.
Cloud object storage
Cloud-based object storage include:
aws- Amazon S3azure- Microsoft Azure Blob Storagegcp- Google Cloud Storageoci- Oracle Cloud Storage1
In each case, we use the vendor’s own SDK/API to provide transparent access to Cloud storage with the additional capability of persistently caching all read data in the AIStore’s remote buckets.
The term “persistent caching” is used to indicate much more than what’s conventionally understood as “caching”: irrespectively of its origin and source, all data inside an AIStore cluster is end-to-end checksummed and protected by the storage services configured both globally and on a per bucket basis. For instance, both remote buckets and ais buckets can be erasure coded, etc.
Notwithstanding, remote buckets will often serve as a fast cache or a fast tier in front of a given 3rd party Cloud storage.
Note that AIS provides multiple easy ways to populate its remote buckets, including - but not limited to - conventional on-demand, self-populating, dubbed cold GET.
Example: accessing Cloud storage via remote AIS
There are, essentially, two different capabilities:
- attach other AIS clusters
- redirect AIS bucket to read, write, and otherwise operate on a different bucket
Here’s a quick and commented example where we access (e.g.) s3://data indirectly, via another bucket called ais://nnn.
Notice that the cluster that contains ais://nnn does no necessarily has to have AWS credentials to access s3://data.
Step 1: show remote cluster
$ ais show remote-cluster
UUID URL Alias Primary Smap Targets Uptime
A9A78a_cSc http://aistore:51080 remais v2145 4 64d23h
Step 2: list s3://data directly via remote cluster
$ AIS_ENDPOINT=http://aistore:51080 ais ls s3://data
NAME SIZE
aaa/bbb/ccc 16.26KiB
aaa/bbb/eee 16.26KiB
aaa/ddd 16.26KiB
aaabbb 16.26KiB
aaaccc 16.26KiB
bbb/111 16.26KiB
ttt/hhh 16.26KiB
ttt/qqq 16.26KiB
Step 3: redirect “local” ais://nnn to Cloud-based s3://data via remote AIS cluster
$ ais bucket props set ais://nnn <TAB-TAB>
backend_bck.name checksum.validate_cold_get lru.enabled ec.bundle_multiplier features
backend_bck.provider checksum.validate_warm_get mirror.copies ec.data_slices write_policy.data
versioning.enabled checksum.validate_obj_move mirror.burst_buffer ec.parity_slices write_policy.md
versioning.validate_warm_get checksum.enable_read_range mirror.enabled ec.enabled
versioning.synchronize lru.dont_evict_time ec.objsize_limit ec.disk_only
checksum.type lru.capacity_upd_time ec.compression access
$ ais bucket props set ais://nnn backend_bck=s3://@A9A78a_cSc/data
"backend_bck.name" set to: "data" (was: "")
"backend_bck.provider" set to: "aws" (was: "")
Bucket props successfully updated.
Note that attached clusters have (human-readable) aliases that often may be easier to use, e.g.:
$ ais bucket props set ais://nnn backend_bck=s3://@remais/data
In other words, actual cluster UUID (A9A78a_cSc above) and its alias (remais) can be used interchangibly.
Step 4: finally, list s3//data via “local” ais://nnn
$ ais ls ais://nnn
aaa/bbb/ccc 16.26KiB
aaa/bbb/eee 16.26KiB
aaa/ddd 16.26KiB
aaabbb 16.26KiB
aaaccc 16.26KiB
bbb/111 16.26KiB
ttt/hhh 16.26KiB
ttt/qqq 16.26KiB
HTTP(S) based dataset
AIS bucket may be implicitly defined by HTTP(S) based dataset, where files such as, for instance:
- https://a/b/c/imagenet/train-000000.tar
- https://a/b/c/imagenet/train-123456.tar
- ...
- https://a/b/c/imagenet/train-999999.tar
would all be stored in a single AIS bucket that would have a protocol prefix ht:// and a bucket name derived from the directory part of the URL Path (“a/b/c/imagenet”, in this case).
WARNING: Currently HTTP(S) based datasets can only be used with clients which support an option of overriding the proxy for certain hosts (for e.g. curl ... --noproxy=$(curl -s G/v1/cluster?what=target_ips)).
If used otherwise, we get stuck in a redirect loop, as the request to target gets redirected via proxy.