AIStore with WebDataset Part 1 -- Storing WebDataset format in AIS
Motivation - High-Performance AI Storage
Training AI models is expensive, so it’s important to keep GPUs fed with all the data they need as fast as they can consume it. WebDataset and AIStore each address different parts of this problem individually:
-
WebDataset is a convenient format and set of related tools for storing data consisting of multiple related files (e.g. an image and a class). It allows for vastly faster i/o by enforcing sequential reads and writes of related data.
-
AIStore provides fast, scalable storage along with powerful features (including co-located ETL) to enhance AI workloads.
The obvious question for developers is how to combine WebDataset with AIStore to create a high performance data pipeline and maximize the features of both toolsets.
In this series of posts, we’ll show how to effectively pair WebDataset with AIStore and how to use AIStore’s inline object transformation and PyTorch DataPipelines to prepare a WebDataset for model training. The series will consist of 3 posts demonstrating the following tasks:
- How to convert a generic dataset to the WebDataset format and store in AIS
- How to create and apply an ETL for on-the-fly sample transformations
- How to set up a PyTorch DataPipeline
For background it may be useful to view the previous post demonstrating basic ETL operations using the AIStore Python SDK.
All code used below can be found here: Inline WebDataset Transform Example
Software
For this example we will be using:
- Python 3.10
- WebDataset Python Library v0.2.48
- AIStore Python SDK v1.2.2
- AIStore Cluster v3.17 -- Running in Kubernetes (see here for local deployment or here for more advanced options)
The Dataset
As in the previous ETL example, we will use the Oxford-IIIT Pet Dataset: https://www.robots.ox.ac.uk/~vgg/data/pets/.
This dataset is notably NOT in WebDataset format -- the class info, metadata, and images are all separated.
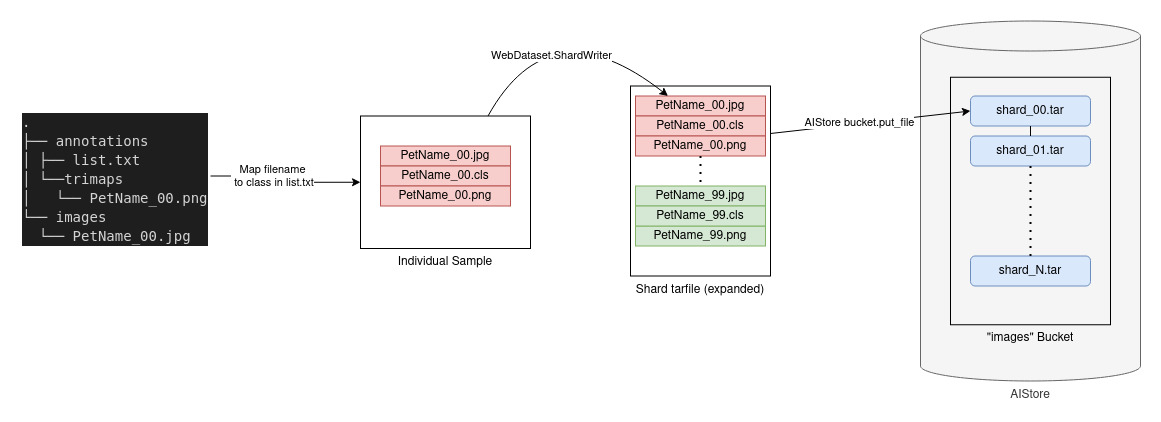
Below is a structured view of the dataset. list.txt contains a mapping from each filename to the class and breed info. The .png files in this dataset are trimap metadata files -- special image files where each pixel is marked as either foreground, background, or unlabeled.
.
├── annotations
│ ├── list.txt
│ ├── README
│ ├── test.txt
│ ├── trainval.txt
│ ├── trimaps
│ │ └── PetName_SampleNumber.png
│ └── xmls
└── images
└── PetName_SampleNumber.jpg
Converting to WebDataset format
There are several ways you could convert a dataset to the WebDataset format, but in this case we will do it via Python using the WebDataset ShardWriter. Notice the callback function provided to upload the results of each created shard to the AIS bucket. For more info on creating WebDatasets check out the video here.
The full code is available here but the key points are shown below:
def load_data(bucket, sample_generator):
def upload_shard(filename):
bucket.object(filename).get_writer().put_file(filename)
os.unlink(filename)
# Writes data as tar to disk, uses callback function "post" to upload to AIS and delete
with wds.ShardWriter("samples-%02d.tar", maxcount=400, post=upload_shard) as writer:
for sample in sample_generator:
writer.write(sample)
sample_generator used above is simply a generator that iterates over the local dataset and yields individual samples in the format below:
{
"__key__": "sample_%04d" % index,
"image.jpg": image_data,
"cls": pet_class,
"trimap.png": trimap_data
}
Note that in the code provided, the sample generator will ignore any records that are incomplete or missing files.
The conversion and resulting structure is shown in the image below, with multiple shards each containing samples grouped by the same base name:
Dsort and Data Shuffling
The above code results in a series of shards in AIStore, but these shards are in the order of the original dataset and are not shuffled in any way, which is likely not what we would want for training.
The AIStore feature dSort can help. It supports shuffling and sorting shards of WebDataset samples, keeping the records (image.jpg, cls, and trimap.png) intact in the output shard.
Below is a visualization of the shuffling process:
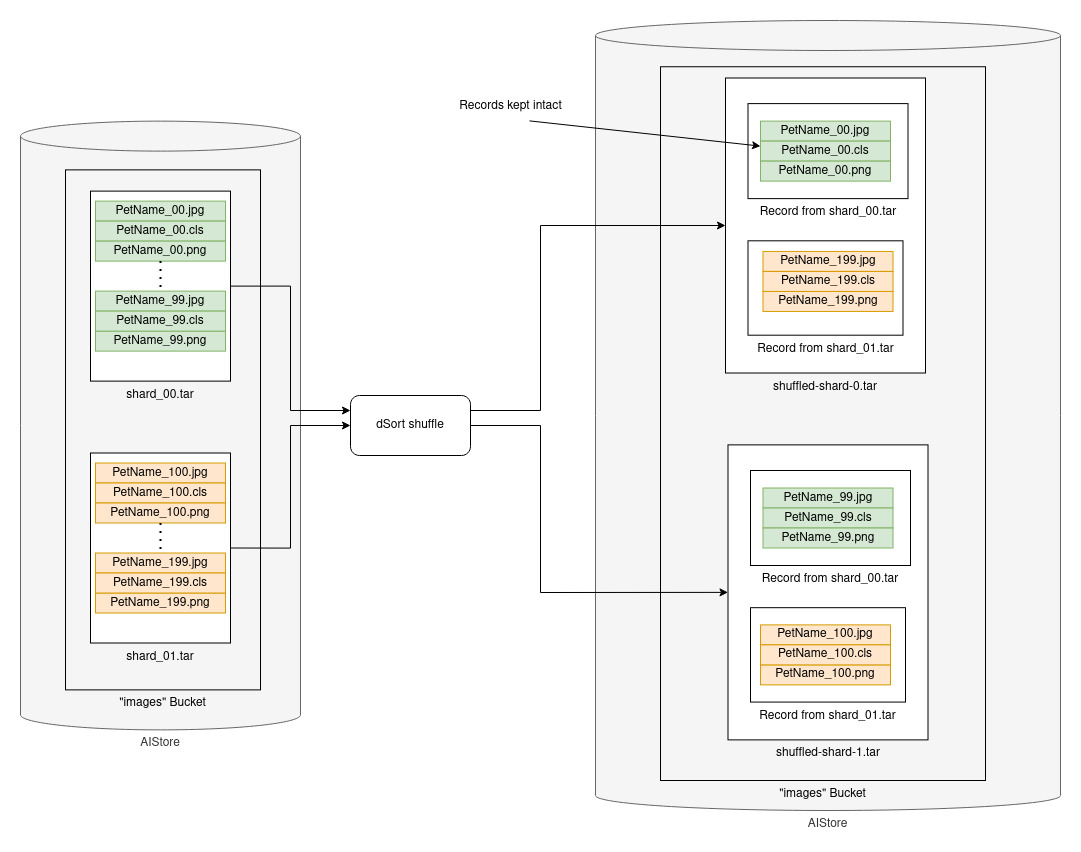
We need to write a dSort spec file to define the job to shuffle and shard our samples. The following spec loads from each of the existing shards, shuffles each record, and creates new shuffled shards of >100MB each. An existing output bucket can also be defined with the output_bck key if desired (other options listed in the docs).
{
"extension": ".tar",
"bck": {"name": "images"},
"input_format": "samples-{00..18}",
"output_format": "shuffled-shard-%d",
"output_shard_size": "100MB",
"description": "Create new shuffled shards",
"algorithm": {
"kind": "shuffle"
}
}
Use the AIS CLI to start the dSort job (no support yet in the AIS Python SDK):
ais start dsort -f dsort_shuffle_samples.json
Wait for the job to complete:
ais wait `YourSortJobID`
Now we can see the output shards as defined in the dSort job spec above, each containing a random set of the data samples.
ais bucket ls ais://images -prefix shuffled
Or with the Python SDK:
import os
from aistore import Client
client = Client(os.getenv("AIS_ENDPOINT"))
objects = client.bucket("images").list_all_objects(prefix="shuffled")
print([entry.name for entry in objects])
Output:
shuffled-shard-0.tar 102.36MiB
shuffled-shard-1.tar 102.44MiB
shuffled-shard-2.tar 102.40MiB
shuffled-shard-3.tar 102.45MiB
shuffled-shard-4.tar 102.36MiB
shuffled-shard-5.tar 102.40MiB
shuffled-shard-6.tar 102.49MiB
shuffled-shard-7.tar 74.84MiB
Finally we have our result: WebDataset-formatted, shuffled shards stored in AIS and ready for use!
In future posts, we’ll show how to run transformations on this data and load it for model training.
References
- GitHub:
- Documentation, blogs, videos:
- https://aiatscale.org
- https://github.com/NVIDIA/aistore/tree/main/docs
- Full code example
- Dataset