AIStore with WebDataset Part 3 -- Building a Pipeline for Model Training
In the previous posts (pt1, pt2), we discussed converting a dataset into shards of samples in the WebDataset format and creating a function to transform these shards using AIStore ETL. For the next step of model training, we must continuously fetch transformed samples from these shards. This post will demonstrate how to use the WebDataset library and PyTorch to generate a DataLoader for the last stage of the pipeline. The final pipeline will transform, decode, shuffle, and batch samples on demand for model training.
Datasets, DataPipes, DataLoaders
Note: The
torchdata.datapipesmodule has been deprecated and removed in recent versions oftorchdata. Some information in this blog post may be outdated.
First, it’s important to understand the difference between each of the PyTorch types:
- Dataset -- Datasets provide access to the data and can either be a map-style or iterable-style.
- TorchData DataPipes -- The beta TorchData library provides DataPipes, which PyTorch calls “a renaming and repurposing of the PyTorch Dataset for composed usage” (see TorchData Github - What are DataPipes?). A subclass of Dataset, DataPipes are a newer implementation designed for more flexibility in designing pipelines and are compatible with the newer DataLoader2.
- DataLoader -- The DataLoader manages interactions with a Dataset, scheduling workers to fetch new samples as needed and performing cross-dataset operations such as shuffling and batching. It is the final step in the pipeline and ultimately provides the arrays of input data to the model for training.
Both WebDataset and AIStore provide their own implementations of these tools:
- The AIStore
AISSourceListeris a TorchDataIterDataPipethat provides the URLs to access each of the provided AIS resources.AISFileListerandAISFileLoaderare also available to load objects directly. In this example we’ll useAISSourceListerto allow WebDataset to handle reading the objects. - The webdataset library’s WebDataset class is an implementation of a PyTorch
IterableDataset. - Webdataset’s WebLoader class wraps the PyTorch
DataLoaderclass, providing an easy way to extend functionality with built-in methods such asshuffle,batch,decode, etc.
Below we’ll go through an example of tying each of these utilities together. The full example code can be found here.
Creating an Iterable Dataset
In part 1 of this series, we uploaded shards of training samples in the WebDataset format. In part 2 we created an AIStore ETL process in our cluster to transform these shards on the server side.
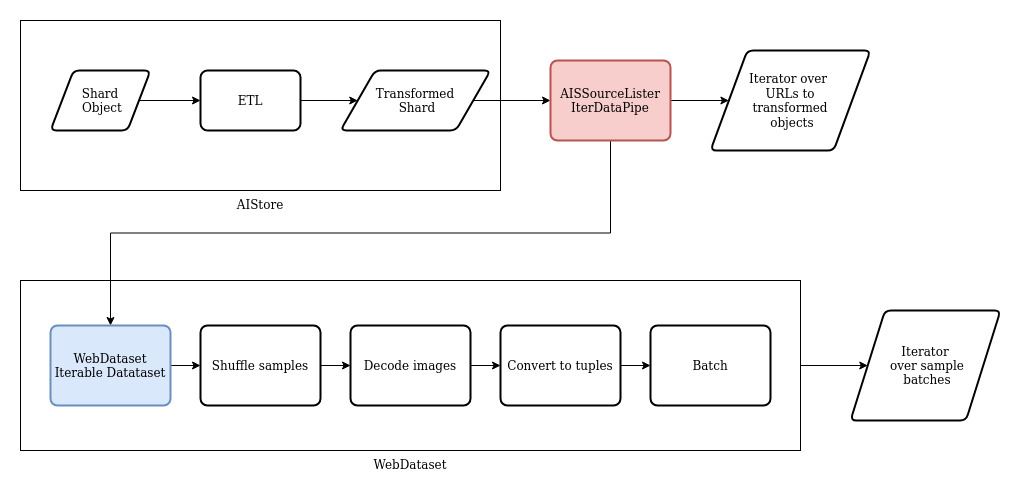
Now that we have the data and the transform function in place, we can use the AISSourceLister Iterable DataPipe to retrieve the URLs to the data we want in AIStore with the ETL transform applied.
- Define the sources in AIS. In this case, we’ll just use every object inside the
imagesbucket created in part 1. - Apply an existing ETL if desired. When the sources provided are read, the ETL will be applied to the objects inline.
- Since WebDataset expects a dictionary of sources, we can apply a simple function to transform each entry to a dictionary.
- Next, we shuffle the sources to avoid any bias from the order of the shards.
sources = AISSourceLister(ais_sources=[bucket], etl_name=etl_name).map(lambda source_url: {"url": source_url})\
.shuffle()
We can now initialize wds.WebDataset by providing our datapipe of dictionaries to object URLs.
WebDataset will then handle fetching the objects and interpreting each individual record inside the object tars.
dataset = wds.WebDataset(sources)
After this step, we now have an iterable dataset over the individual samples and can use any of the WebDataset built-in functions to modify them (see the WebDataset README). Here we’ll shuffle the samples in each shard, decode the image files to tensors, and convert to batches of tuples. Since we expect to use multiple dataset workers, each operating in their own subprocess, we’ll batch the samples here to reduced the overhead of unpacking the samples in the main process.
Full WebDataset creation code:
def create_dataset() -> wds.WebDataset:
bucket = client.bucket(bucket_name)
# Get a list of urls for each object in AIS, with ETL applied, converted to the format WebDataset expects
sources = AISSourceLister(ais_sources=[bucket], etl_name=etl_name).map(lambda source_url: {"url": source_url})\
.shuffle()
# Load shuffled list of transformed shards into WebDataset pipeline
dataset = wds.WebDataset(sources)
# Shuffle samples and apply built-in webdataset decoder for image files
dataset = dataset.shuffle(size=1000).decode("torchrgb")
# Return iterator over samples as tuples in batches
return dataset.to_tuple("cls", "image.jpg", "trimap.png").batched(16)
Creating a DataLoader
With a dataset defined, we can now use the webdataset WebLoader class, introduced above, to manage retrieving data from the dataset.
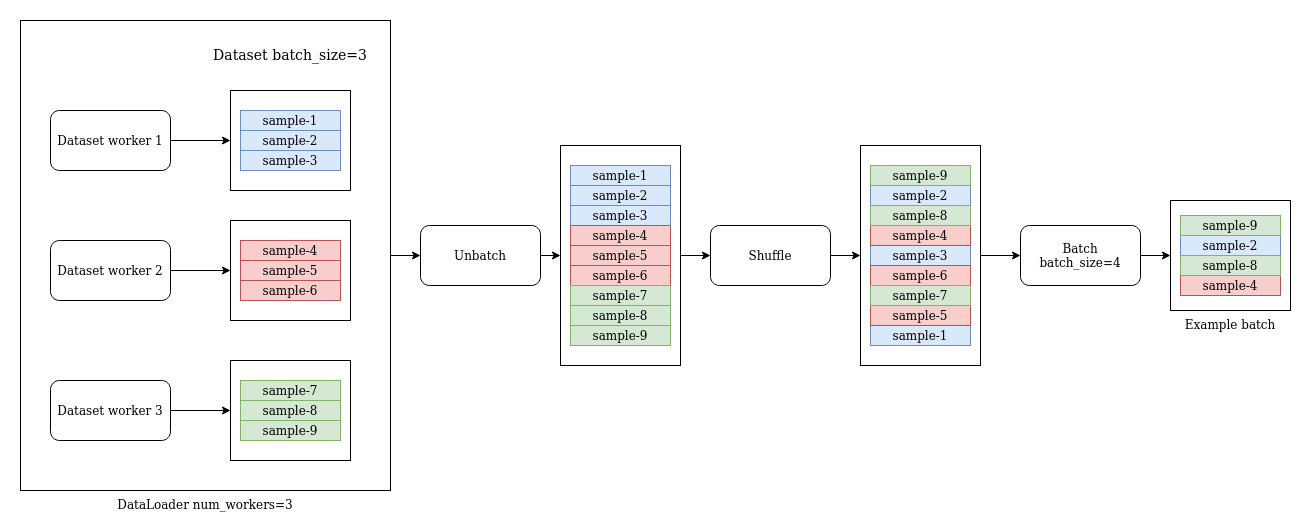
WebLoader allows us to parallelize loading from the dataset using multiple workers, then shuffle and batch the samples for training.
Here we create a WebLoader with 4 dataset workers.
Each of those workers will execute the process defined in the dataset to fetch an object in AIS, parse into samples, and return a batch.
Note batch_size in the WebLoader below is set to None because each dataset worker will do its own batching and yield a batch of 16 samples.
We can then use the WebLoader FluidInterface functionality to first unbatch the minibatches of samples from each of our dataset workers, shuffle across a defined number of samples (1000 in the example below), and then rebatch into batches of the size we actually want to provide to the model.
def create_dataloader(dataset):
loader = wds.WebLoader(dataset, num_workers=4, batch_size=None)
return loader.unbatched().shuffle(1000).batched(64)
A simplified version of this pipeline with a 3 dataset workers, a dataset batch size of 3, and a final batch size of 4 would look like this:
Results
Finally, we can inspect the results generated by the DataLoader, ready for model training. Note that none of the pipeline actually runs until the DataLoader requests the next batch of samples.
def view_data(dataloader):
# Get the first batch
batch = next(iter(dataloader))
classes, images, trimaps = batch
# Result is a set of tensors with the first dimension being the batch size
print(classes.shape, images.shape, trimaps.shape)
# View the first images in the first batch
show_image_tensor(images[0])
show_image_tensor(trimaps[0])
References
- GitHub:
- Documentation, blogs, videos:
- https://aiatscale.org
- https://github.com/NVIDIA/aistore/tree/main/docs
- PyTorch intro to Datasets and DataLoaders: https://pytorch.org/tutorials/beginner/basics/data_tutorial.html
- Discussion on Datasets, DataPipes, DataLoaders: https://sebastianraschka.com/blog/2022/datapipes.html
- Full code example
- Dataset